Кодировка UTF-8 представляет текст в виде последовательности байтов, где символы Unicode занимают от 1 до 4 байтов. Она совместима с ASCII, что позволяет корректно обрабатывать файлы в системах, изначально ориентированных на английский текст. Вариант без BOM означает отсутствие в начале файла сигнатуры из трёх байтов (EF BB BF), которая обычно указывает программе на используемую кодировку.
Использование UTF-8 без BOM рекомендуется при разработке веб-страниц, скриптов и конфигурационных файлов, так как многие интерпретаторы и серверы могут некорректно обрабатывать BOM. Например, PHP при наличии BOM до тега <?php может вывести лишние символы, нарушая работу HTTP-заголовков. В JSON и XML лишние байты в начале файла также могут вызвать ошибки парсинга.
Выбор формата без BOM упрощает интеграцию между разными системами, особенно при обмене данными через API. При этом, чтобы избежать проблем с определением кодировки, необходимо явно указывать charset=UTF-8 в заголовках HTTP или в метатегах HTML. Такой подход обеспечивает полную совместимость и предсказуемое отображение символов на всех платформах.
Что означает кодировка UTF-8 без BOM
UTF-8 – способ кодирования Unicode в последовательность байтов; «без BOM» означает, что файл не содержит предварительной метки порядка байтов (Byte Order Mark) U+FEFF. В UTF-8 эта метка представлена трёхбайтовой сигнатурой 0xEF 0xBB 0xBF (hex). Отсутствие BOM гарантирует, что файл начинается сразу с полезных данных – никаких служебных байтов в начале.
Практические рекомендации: для веба, JSON, JavaScript, CSS, Bash/Python/Perl/Go скриптов и любых файлов с shebang – сохраняйте UTF-8 без BOM. Для взаимодействия с устаревшими Windows-приложениями можно временно использовать BOM, но не как дефолт в проектах с кросс-платформенной разработкой.
Как проверить наличие BOM: посмотреть первые байты файла. Быстрая проверка в терминале: xxd -l 3 file | awk '{print $2 $3 $4}' – вернёт efbbbf, если BOM есть. Другой способ: hexdump -n 3 -C file. В текстовом редакторе первые символы могут выглядеть как невидимый символ или «ï» перед текстом.
Как удалить BOM безопасно: командные примеры – POSIX: tail -c +4 src > dst (пропустить первые 3 байта); в bash/sed: sed -i $'1s/^\\xEF\\xBB\\xBF//' file; с Python (универсально): python -c "import sys; b=sys.stdin.buffer.read(); sys.stdout.buffer.write(b.decode('utf-8-sig').encode('utf-8'))". В редакторах (VS Code, Sublime, Notepad++) выбрать «UTF-8 (без BOM)» при сохранении.
Настройка CI/репозитория: приёмлемая практика – встроить проверку в pre-commit (hook), которая отклоняет файлы с BOM, и документировать в CONTRIBUTING требование «UTF-8 без BOM». Для Git можно использовать текстовых атрибутов и скриптов, нормализующих кодировку при коммите.
Когда BOM полезен: в UTF-16/UTF-32 BOM служит для указания порядка байтов; в UTF-8 BOM иногда помогает старым Windows-инструментам определить кодировку. Тем не менее, для современных приложений и межплатформенных проектов BOM в UTF-8 – источник проблем, а не преимущество.
Как отличить файл UTF-8 без BOM от файла с BOM в hex-редакторе и командной строке

В hex-редакторе наличие BOM определяется первыми тремя байтами файла. Для UTF-8 с BOM в начале всегда присутствует последовательность EF BB BF. Если файл закодирован в UTF-8 без BOM, эти байты отсутствуют, и первый видимый байт относится уже к содержимому текста.
Например, файл с BOM при открытии в hex-редакторе может начинаться так: EF BB BF 41 42 43 (где 41 42 43 – это ASCII-коды символов «ABC»). Файл без BOM для того же текста будет выглядеть как 41 42 43 без дополнительных байт в начале.
В Windows аналогичную проверку можно выполнить с помощью certutil -dump имя_файла | more и анализа первых трех байт. Отсутствие последовательности EF BB BF в начале означает UTF-8 без BOM.
Почему некоторые текстовые парсеры и скрипты ломаются при наличии BOM
UTF-8 BOM – три байта 0xEF 0xBB 0xBF в начале файла. Хотя BOM не меняет кодировка символов, эти три байта остаются видимыми как данные и нарушают предположение многих парсеров и рантаймов, что файл начинается с синтаксического токена или ASCII-заголовка.
- Нарушение сигнатуры/шаблона первой строки. Скрипты с
#!(shebang) перестают распознаваться, если перед#стоят невидимые байты – интерпретатор получает некорректную строку и выдает «bad interpreter» или игнорирует shebang. - Проблемы с формальными форматами. CSV/TSV и простые парсеры, читающие первые байты как разделители/заголовки, встречают неожиданные символы и неправильно сопоставляют столбцы.
- JSON и некоторые JSON-парсеры. Несмотря на то что современный JSON-парсер может поддерживать BOM, ряд реализаций (особенно старых или минимальных) считает первые байты частью текста и бросает ошибку синтаксического анализа.
- XML и HTTP-заголовки. XML-процессоры зависят от первой строки (). BOM до декларации XML может привести к ошибкам обработки. BOM в ответе HTTP перед заголовками ломает протокол (например, при прямой записи в сокет), т.к. заголовки должны начинаться сразу.
- Проверки контрольной суммы и цифровые подписи. Хеши/подписи вычисляются по байтам; добавление BOM изменяет вход для подписи, что делает проверку недействительной.
- Регулярные выражения и маркеры начала строки. Использование якоря
^ожидает первый видимый символ; BOM нарушает матчи, особенно если обработчик не рассматривает BOM как нулевой-width.
Частые конкретные проявления (с примерами):
- Unix: скрипт
#!/usr/bin/env python3с BOM – при запуске «/usr/bin/env: ‘\xef\xbb\xbf#!/usr/bin/env’: No such file or directory». - Node.js:
require('./file.json')может выбросить «Unexpected token» при наличии BOM в JSON, если парсер не удаляет BOM. - PHP: включение файла через
includeс BOM может вывести пробельный символ до заголовков и вызвать «Headers already sent» при работе с сессиями или перенаправлениями.
Как обнаружить BOM:
- Команда:
hexdump -C file | head– в начале файла должны бытьef bb bf. - Python:
open('file','rb').read(3)==b'\\xef\\xbb\\xbf'.
Надёжные рекомендации по предотвращению и устранению:
- По возможности сохранять текстовые файлы как UTF-8 without BOM (настройка редактора/IDE: «UTF-8 (no BOM)»).
- При чтении входных данных очищать BOM на уровне загрузчика, не в прикладной логике:
- Python:
open('file', encoding='utf-8-sig')– автоматически удаляет BOM. - JavaScript (Node):
if (buf[0]===0xEF && buf[1]===0xBB && buf[2]===0xBF) buf = buf.slice(3); - PHP:
$s = preg_replace('/^\x{EF}\x{BB}\x{BF}/', '', $s);или читать через stream и удалять первые три байта при наличии.
- Python:
- Для сетевых протоколов формировать заголовки/метаданные отдельными вызовами до записи тела; никогда не писать прямо байты файла в ответ без проверки на BOM.
- В системах с цифровыми подписями – стандартизировать формат (например, всегда подписывать UTF-8 без BOM) и документировать это требование.
- В CI/пайплайнах добавить проверку на BOM (скрипт, который сканирует и либо отклоняет коммит, либо устраняет BOM автоматически).
- При интероперабельности между языками документировать ожидания по начальным байтам; если библиотека не удаляет BOM, делать это на этапе парсера/входного адаптера.
Практические команды для массовой очистки:
- Unix (удалить BOM из файла):
tail -c +4 file > file.clean– безопасно, если точно есть BOM. - Однострочная sed (GNU sed с поддержкой escape):
sed '1s/^\xEF\xBB\xBF//' file > file.clean. - iconv для конвертации и удаления некорректных последовательностей:
iconv -f utf-8 -t utf-8 -o file.clean file(не всегда удаляет BOM – проверяйте).
Контрольные пункты при разработке парсеров и скриптов:
- Явно проверяйте и при необходимости убирайте BOM в самом начале потока ввода.
- Не полагайтесь на «тихий» нормализатор в библиотеке – документируйте поведение и обрабатывайте исключения.
- Тестируйте сценарии с BOM: unit-тесты должны покрывать файлы с и без BOM для тех форматов, которые вы поддерживаете.
- Логируйте случаи, когда вход содержит невидимые начальные байты – это часто указывает на проблемы в цепочке инструментов/редакторов.
Как сохранить файл в UTF-8 без BOM в VS Code, Notepad++ и Sublime Text
VS Code: Откройте файл, нажмите на индикатор кодировки в правом нижнем углу, выберите «Сохранить с кодировкой» → «UTF-8». Убедитесь, что в настройках "files.encoding" установлено "utf8", а "files.autoGuessEncoding" отключено. При выборе «UTF-8» в VS Code используется вариант без BOM.
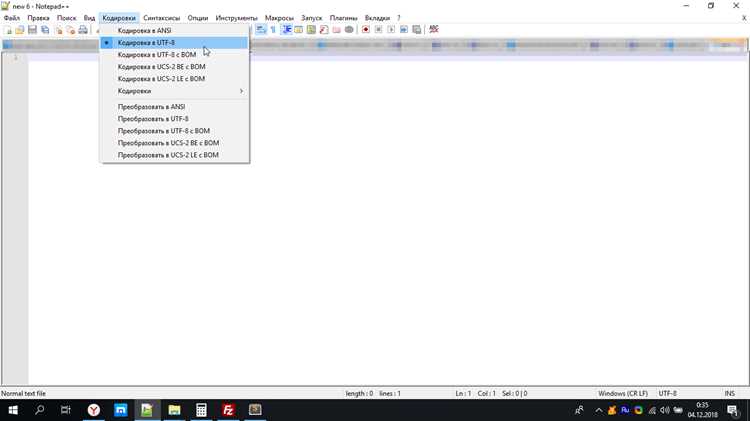
Notepad++: В меню «Кодировка» выберите «Преобразовать в UTF-8 (без BOM)» и сохраните файл. Для автоматического сохранения новых файлов без BOM откройте «Настройки» → «Настройки…», раздел «Новый документ», установите кодировку «UTF-8 без BOM».
Sublime Text: Откройте «Preferences» → «Settings» и добавьте параметр "default_encoding": "UTF-8" вместе с "save_with_bom": false. При сохранении текущего файла можно выполнить команду «File» → «Save with Encoding» → «UTF-8».
Как обрабатывать и принудительно удалить BOM в Python, JavaScript и PHP

Python: При чтении файлов используйте двоичный режим и удаляйте сигнатуру EF BB BF вручную. Пример:
with open('file.txt', 'rb') as f:
data = f.read()
if data.startswith(b'\xef\xbb\xbf'):
data = data[3:]
text = data.decode('utf-8')JavaScript (Node.js): Чтение как буфера и проверка первых байт:
const fs = require('fs');
let data = fs.readFileSync('file.txt');
if (data[0] === 0xEF && data[1] === 0xBB && data[2] === 0xBF) {
data = data.slice(3);
}
const text = data.toString('utf8');PHP: Используйте file_get_contents() и substr() для удаления BOM:
<?php
$data = file_get_contents('file.txt');
if (substr($data, 0, 3) === "\xEF\xBB\xBF") {
$data = substr($data, 3);
}
?>Влияние отсутствия BOM на передачу текста через HTTP и API (заголовки, Content-Type)

Отсутствие BOM (Byte Order Mark) не меняет саму кодировку UTF-8, но меняет способ, которым получатель определяет кодировку при недостатке явной информации. В API это критично: надёжная интерпретация текста должна опираться на правильные HTTP-заголовки и форматы сообщений, а не на присутствие/отсутствие BOM.
Ключевые факты и практические правила:
1) Заголовок Content-Type = «тип/подтип; charset=…» является первичным источником кодировки для HTTP-клиентов. Для текстовых типов без указания charset многие клиенты/прокси могут применять старые дефолты (HTTP/1.1: text/* → ISO-8859-1) – это приводит к искажению символов при отсутствии BOM. Всегда указывайте charset для text/* и для других текстовых медиа-типов, если сервер уверенно использует UTF-8.
2) Для application/json по RFC (RFC 8259) стандартной кодировкой является UTF-8; указание «charset=utf-8» в заголовке необязательно, но полезно для совместимости с инструментами, которые не читают RFC. JSON-парсеры во многих языках корректно обрабатывают UTF-8 без BOM; наличие BOM в JSON иногда вызывает ошибку парсинга (вставка U+FEFF до ‘{‘ – лишний символ).
3) XML-прикладные форматы полагаются на порядок детекции: BOM → декларация → эвристика/дефолт. Если BOM отсутствует и XML-декларация отсутствует, парсер может предположить UTF-8, но поведение зависит от реализации. Поэтому для XML указывайте и Content-Type (application/xml или text/xml) с charset и/или XML-декларацию;
4) В веб-браузерах и XHR/Fetch алгоритм декодирования использует Content-Type; если его нет/неверный, браузер применит heuristics/пользовательские настройки, что приведёт к разным результатам на разных клиентах. Для REST API единственно надёжный подход – явный заголовок.
5) BOM в начале тела ответа изменяет смещение байтов – если Content-Length рассчитывается заранее на основе контента без BOM, вставка BOM ломает подсчёт длины и может некорректно работать с некоторыми прокси/серверными реализациями. Удаляйте BOM в конце серверной генерации и вычисляйте Content-Length по итоговому байтовому потоку.
6) На стороне приёма: всегда нормализуйте вход (удаляйте возможный U+FEFF в начале) перед парсингом JSON/CSV/проч. Это защищает от вставленных BOM в файлах от клиентов, особенно при интеграциях с Windows-инструментами.
| Content-Type | Поведение без BOM (практика) | Рекомендация (конкретно) |
|---|---|---|
| application/json | По RFC – UTF-8; многие парсеры ожидают UTF-8. BOM лишний и может сломать парсинг. | Отправлять: Content-Type: application/json; charset=utf-8. Удалять BOM из тела. На приёме – предварительно trim U+FEFF перед JSON.parse. |
| text/plain, text/html | Если charset не указан, старый HTTP дефолт – ISO-8859-1; браузеры могут применить автопоиск. Отсутствие BOM → возможные искажения. | Всегда указывать: Content-Type: text/html; charset=utf-8 или text/plain; charset=utf-8. Не использовать BOM на сервере. |
| application/xml / text/xml | Парсеры читают BOM → декларацию → эвристику; без BOM и декларации поведение зависит от реализации (часто UTF-8). | Добавить XML-декларацию: Content-Type: application/xml; charset=utf-8. Избегать BOM для совместимости. |
| CSV/TSV (text/*) | Клиенты часто полагаются на BOM для определения UTF-8; без BOM и без charset – риск прочтения в локальной кодировке (Windows-1251 и т.п.). | Для API: передавать как text/csv; charset=utf-8. Для файлов, предназначенных для Excel, при необходимости использовать UTF-8 без BOM + явную инструкцию по импорту или использовать UTF-16LE с BOM только если целевая среда требует. |
Практические примеры заголовков и действий:
– Сервер (пример): HTTP/1.1 200 OK, Content-Type: application/json; charset=utf-8, вычислить Content-Length по уже окончательному байтовому массиву (без последующего добавления BOM).
– Клиент (JS): перед JSON.parse выполнять: if (text.charCodeAt(0) === 0xFEFF) text = text.slice(1); Это безопасно и предотвращает ошибки при случайном BOM.
– CI/обработка файлов: на этапе приёма/валидации данных приводите все входы к UTF-8 без BOM (utf8-normalize), логируйте случаи обнаружения BOM для источников, которые их присылают.
Контрольные проверки перед развёртыванием API:
– убедиться, что серверные шаблоны/файлы исходников не содержат BOM (часто появляется в PHP/Python-файлах от редакторов);
– протестировать ответы через curl: curl -I https://api.example/endpoint – проверить Content-Type; затем curl -s https://api.example/endpoint | xxd | head – убедиться, что первые байты не 0xEF 0xBB 0xBF;
– в нагрузочном тесте прокси и CDN: проверить, не удаляют/не меняют charset и не добавляют/не удаляют BOM.
Как избежать ошибок при импорте CSV/JSON в базы данных из файлов с BOM
Перед загрузкой файлов проверьте наличие BOM с помощью hex-редактора или утилит file и xxd. Для UTF-8 BOM кодируется как байты EF BB BF в начале файла. Если они присутствуют, удалите их.
Для CSV используйте текстовые процессоры или конвертеры (iconv, dos2unix) с указанием кодировки UTF-8 без BOM. При работе в Excel сохраняйте через «CSV UTF-8 (без BOM)» либо экспортируйте из LibreOffice Calc с опцией Edit filter settings и снятой галочкой «Save with BOM».
Для JSON в скриптах на Python можно удалять BOM вызовом data = data.lstrip('\ufeff') перед парсингом. В Node.js используйте fs.readFileSync(file, 'utf8').replace(/^\uFEFF/, ''). Это исключает ошибку синтаксиса при загрузке в СУБД.
В PostgreSQL перед COPY или \copy можно предварительно фильтровать поток через sed '1s/^\xEF\xBB\xBF//'. В MySQL – загружать через LOAD DATA только после очистки BOM, иначе первый столбец получит искажённое имя.
Автоматизируйте проверку в ETL-процессах: добавьте шаг валидации загружаемых файлов, который отбрасывает первые три байта, если они равны EF BB BF. Это гарантирует корректную структуру данных в базе.
Вопрос-ответ:
Почему в некоторых случаях выбирают именно UTF-8 без BOM?
UTF-8 без BOM удобен, если файл должен быть совместим с системами и программами, которые могут некорректно обрабатывать отметку BOM в начале текста. Например, некоторые веб-серверы или интерпретаторы скриптов при обнаружении BOM добавляют лишние символы в вывод, что может ломать структуру HTML или JSON. Поэтому для веб-разработки часто используют именно вариант без BOM.
Что такое BOM в кодировке UTF-8?
BOM (Byte Order Mark) — это специальная последовательность байтов в начале файла, которая сигнализирует программе, что текст записан в определённой кодировке и порядке байтов. Для UTF-8 это три байта: EF BB BF. Хотя BOM полезен для некоторых программ, он не обязателен для UTF-8, так как эта кодировка не зависит от порядка байтов.
Может ли файл без BOM отображаться неправильно?
Да, такое возможно, но редко. Если программа не умеет автоматически определять кодировку и рассчитывает на BOM как подсказку, она может попытаться интерпретировать текст в другой кодировке, что приведёт к искажению символов. Однако большинство современных редакторов и браузеров распознают UTF-8 без BOM без проблем.
Как проверить, есть ли в файле BOM?
Один из способов — открыть файл в шестнадцатеричном редакторе и посмотреть первые три байта. Если это EF BB BF, значит BOM присутствует. В текстовых редакторах вроде Notepad++ можно просто открыть файл и посмотреть в статусной строке тип кодировки: будет указано «UTF-8 BOM» или «UTF-8».
Можно ли удалить BOM из уже созданного файла?
Да, это легко сделать. В большинстве редакторов при сохранении можно выбрать вариант кодировки без BOM. Например, в Visual Studio Code нужно открыть меню «Сохранить с кодировкой» и выбрать «UTF-8». При этом файл сохранится без начальных байтов BOM, а содержимое останется прежним.