

Машинное обучение стало неотъемлемой частью современных технологий, с его помощью решаются задачи от классификации данных до предсказания трендов. В этой статье мы подробно рассмотрим основные модели машинного обучения, их применение и особенности. Каждая модель имеет свои преимущества и ограничения в зависимости от специфики задачи и структуры данных.
Линейная регрессия – одна из самых простых и часто используемых моделей в машинном обучении. Она применяется для предсказания числовых значений, основываясь на линейной зависимости между переменными. Используется, например, в эконометрике для прогнозирования цен или в медицине для оценки вероятности заболевания. Важно учитывать, что линейная регрессия не будет эффективно работать в случае сложных нелинейных зависимостей.
Решающие деревья – алгоритм, который строит модель в виде дерева решений. Каждое разделение в дереве представляет собой условие, которое классифицирует данные на основе их признаков. Это одна из самых популярных моделей для задач классификации и регрессии. Однако решающие деревья могут легко переобучаться, что требует применения методов регуляризации, таких как случайные леса или градиентный бустинг.
Нейронные сети – модели, имитирующие работу мозга человека, состоящие из множества взаимосвязанных узлов (нейронов). Эти модели особенно полезны в задачах, где важно учитывать сложные, многомерные связи между данными, такие как в обработке изображений или аудио. Однако нейронные сети требуют большого объема данных и вычислительных ресурсов, что может ограничивать их использование в некоторых сферах.
Метод опорных векторов (SVM) – используется для классификации и регрессии. Он находит гиперплоскость, которая разделяет данные на классы с максимальным отступом между ними. Этот метод особенно эффективен для задач с высокоразмерными данными, например, для классификации текстов или изображений. Одним из основных недостатков SVM является высокая вычислительная сложность при работе с большими наборами данных.
Методы ансамблирования включают такие техники, как случайный лес и градиентный бустинг. Эти методы объединяют несколько моделей для улучшения точности предсказаний. Например, случайный лес создает множество решающих деревьев и усредняет их результаты, что снижает вероятность переобучения. Градиентный бустинг, наоборот, строит модель, корректируя ошибки предыдущих деревьев, что часто приводит к улучшению качества прогнозов.
Каждая из моделей машинного обучения может быть оптимизирована для конкретных типов данных и задач. Выбор подходящего алгоритма зависит от целей анализа, объема и качества данных, а также от ресурсов, доступных для обучения модели.
Как выбрать подходящую модель машинного обучения для задачи классификации
При решении задачи классификации важно учитывать несколько факторов, чтобы выбрать наиболее подходящую модель машинного обучения. Оценка этих факторов позволит повысить точность и эффективность работы модели.
1. Размер и качество данных: Если у вас ограниченный объем данных, модели, требующие большого числа примеров для обучения, такие как глубокие нейронные сети, могут не подойти. Для небольших наборов данных лучше использовать более простые модели, такие как логистическая регрессия или деревья решений. Когда данных много и они разнообразны, можно использовать более сложные модели, такие как случайные леса или SVM.
2. Тип задачи классификации: Задачи могут быть бинарными или многоклассовыми. Для бинарной классификации логистическая регрессия или SVM являются хорошими выборами, если данные линейно разделимы. Для многоклассовых задач лучше подойдут случайные леса, градиентный бустинг или нейронные сети.
3. Производительность и время обучения: Для задач, где требуется быстрое обучение и предсказания, стоит выбирать модели с меньшей вычислительной нагрузкой, такие как наивный Байес или линейные модели. Если задача требует высокой точности, а время обучения не критично, можно рассмотреть более сложные методы, такие как глубокие нейронные сети.
4. Требования к интерпретируемости модели: Если важно понимать, как модель принимает решения, предпочтение стоит отдать моделям, которые предоставляют интерпретируемые результаты, таким как логистическая регрессия или деревья решений. Если объяснимость не является критичной, можно использовать более сложные модели, такие как случайные леса или градиентный бустинг.
5. Риск переобучения: Для предотвращения переобучения необходимо внимательно выбирать параметры модели. Простые модели, такие как наивный Байес, подвержены меньшему риску переобучения, в то время как более сложные модели, например, глубокие нейронные сети, требуют регуляризации или кросс-валидации для минимизации этого риска.
6. Потребности в масштабируемости: Если задача требует масштабируемости на больших объемах данных, стоит рассматривать модели, которые хорошо масштабируются, такие как случайные леса или градиентный бустинг, или использовать подходы, основанные на распределенных вычислениях, например, нейронные сети в распределенных системах.
Применение регрессии в машинном обучении для предсказания числовых значений
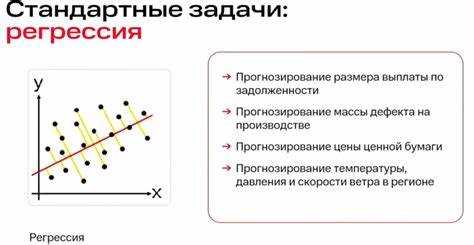
Регрессия – один из ключевых методов в машинном обучении, используемый для предсказания числовых значений на основе имеющихся данных. Это метод, при котором модель обучается на исторических данных для выявления зависимости между независимыми переменными (фичами) и зависимой переменной (целевой). Основная задача регрессии заключается в построении функции, которая позволяет прогнозировать числовые значения с минимальной ошибкой.
Наиболее популярными типами регрессий являются линейная и полиномиальная. Линейная регрессия предполагает, что зависимость между переменными можно описать прямой линией. Этот подход идеально подходит для простых задач, например, предсказания цен на недвижимость или уровня доходов на основе нескольких факторов. Однако, если данные более сложны и не поддаются линейному моделированию, используется полиномиальная регрессия, которая может лучше описать более сложные зависимости.
Одним из распространенных примеров применения регрессии является предсказание потребительских показателей, таких как цены на товары или спрос на продукты. В таких случаях модель обучается на данных о продажах, ценах, сезонных факторах и других характеристиках. Еще одним примером является использование регрессии в здравоохранении для предсказания значений различных биологических параметров, например, уровня сахара в крови на основе ряда факторов, таких как возраст, вес и уровень физической активности.
Регрессионные модели также широко используются в финансовом секторе для предсказания цен на акции, прогнозирования рисков и анализа кредитоспособности клиентов. В таких приложениях точность прогноза напрямую зависит от качества данных и правильности выбора модели. Одним из важных аспектов является регуляризация модели для предотвращения переобучения (overfitting), что особенно важно при работе с большими объемами данных.
Для достижения максимальной точности в задачах регрессии важно использовать различные методы предобработки данных, такие как нормализация и очистка от выбросов. Также стоит уделить внимание выбору правильной метрики для оценки качества модели, например, среднеквадратичная ошибка (MSE) или коэффициент детерминации (R²), который показывает, насколько хорошо модель объясняет вариацию данных.
Таким образом, регрессия является мощным инструментом для предсказания числовых значений и применяется во множестве областей, от финансов до медицины. Важно правильно выбирать тип модели, проводить качественную предобработку данных и регулярно оценивать эффективность предсказаний.
Особенности использования нейронных сетей в глубоких моделях обучения
В отличие от традиционных методов машинного обучения, нейронные сети способны автоматически обучаться без необходимости явного задания признаков. Это позволяет использовать их в задачах, где явное описание данных невозможно или крайне сложно, например, в обработке изображений или естественного языка. Одной из ключевых особенностей является использование функций активации, таких как ReLU, sigmoid или tanh, которые помогают нейронной сети вводить нелинейность в модель и тем самым обучать более сложные зависимости.
Нейронные сети хорошо работают в задачах классификации, регрессии и сегментации, особенно когда речь идет о больших данных. Например, сверточные нейронные сети (CNN) эффективно решают задачи компьютерного зрения, а рекуррентные нейронные сети (RNN) – задачи с временными рядами или текстовыми данными. Важно отметить, что для улучшения качества обучения необходимо использовать методы регуляризации, такие как dropout, чтобы предотвратить переобучение.
Одним из вызовов при использовании нейронных сетей является необходимость работы с большими вычислительными ресурсами, особенно при обучении сложных моделей на крупных датасетах. В таких случаях используются графические процессоры (GPU) и распределенные вычислительные платформы, что значительно ускоряет процесс обучения. Кроме того, важной особенностью является настройка гиперпараметров, таких как размер пакета (batch size), скорость обучения и количество слоев, что существенно влияет на производительность модели.
Использование предобученных моделей, таких как transfer learning, позволяет существенно сократить время обучения и улучшить точность при ограниченных ресурсах. Это особенно важно в тех случаях, когда доступные данные недостаточны для обучения модели с нуля. С помощью предобученных сетей можно извлечь полезные признаки из других задач и адаптировать их для конкретной проблемы, что повышает эффективность процесса обучения.
Как использовать модели на основе деревьев решений для анализа данных

Модели на основе деревьев решений, такие как классификация и регрессия, широко применяются для анализа данных благодаря своей простоте, наглядности и интерпретируемости. Эти модели делят данные на группы с использованием структуры дерева, где каждый узел представляет собой тест на некоторую характеристику, а каждый лист – результат классификации или предсказания.
Для начала, при использовании дерева решений для анализа данных, важно выбрать правильную метрику для оценки качества модели. Наиболее часто используются:
- Индекс Джини – мера, используемая в алгоритмах классификации, показывающая степень неоднородности данных в узле.
- Кросс-энтропия (или логарифмическая потеря) – мера, оценивающая различие между истинными метками и предсказанными.
- Среднеквадратическая ошибка (MSE) – для задач регрессии, показывающая разницу между предсказанными значениями и реальными результатами.
Деревья решений, как правило, страдают от проблемы переобучения, особенно при глубоком разветвлении. Чтобы избежать этого, важно использовать технику обрезки (pruning), которая помогает уменьшить размер дерева, исключив несущественные узлы. Кроме того, для улучшения устойчивости модели можно использовать ансамблевые методы, такие как случайный лес и градиентный бустинг, которые комбинируют множество деревьев решений для получения более точных и стабильных предсказаний.
В процессе обучения дерева решений важна настройка гиперпараметров, таких как максимальная глубина дерева, минимальное количество образцов в листе и минимальное количество образцов для разделения узла. Для поиска оптимальных значений этих параметров можно использовать методы перекрестной проверки (cross-validation) и сеточный поиск (grid search).
Применение дерева решений в задачах анализа данных позволяет легко визуализировать процесс принятия решений. Например, в задачах классификации можно построить графическое представление дерева, что поможет понять, какие признаки наиболее важны для принятия решения.
Некоторые из основных областей применения деревьев решений включают:
- Анализ покупательского поведения в маркетинге.
- Диагностика заболеваний в медицинских исследованиях.
- Прогнозирование финансовых рисков и дефолтов.
- Определение факторов, влияющих на качество продукции на производстве.
Кроме того, дерево решений можно использовать для создания простых, но мощных моделей, которые обеспечивают интуитивно понятные результаты и легко поддаются объяснению заинтересованным сторонам. Однако важно помнить, что они не всегда могут быть такими же точными, как более сложные модели, такие как нейронные сети, особенно при наличии сложных зависимостей в данных.
Группировка и кластеризация данных с помощью алгоритмов машинного обучения

Один из самых популярных алгоритмов для кластеризации – это K-средних (K-means). Этот метод требует задать количество кластеров заранее, после чего алгоритм итеративно назначает объекты к ближайшему центроиду, обновляя его до тех пор, пока не будет достигнута стабильность. Однако, параметр K (количество кластеров) часто сложно выбрать, и для этого могут использоваться такие методы, как метод локтя или силует.
Другим подходом является иерархическая кластеризация, которая строит дендрограмму – дерево, показывающее, как объекты объединяются на разных уровнях сходства. Этот метод не требует предварительно заданного количества кластеров и может быть полезен, когда необходимо исследовать структуру данных на разных уровнях. Однако он может быть вычислительно дорогим для больших наборов данных.
Для более сложных данных, содержащих нелинейные зависимости, часто применяются алгоритмы, такие как DBSCAN (Density-Based Spatial Clustering of Applications with Noise). DBSCAN разделяет данные на кластеры на основе плотности точек и способен выделять шумовые (выбивающиеся) точки, что делает его эффективным для данных с различной плотностью.
Кроме того, методы, основанные на моделях, такие как алгоритм Gaussian Mixture Model (GMM), позволяют моделировать данные как смесь нескольких гауссовых распределений. Эти методы полезны, когда кластеры имеют сложную форму и распределение, не ограничиваясь жесткими границами, как в случае с K-средними.
Для выбора подходящего алгоритма кластеризации важно учитывать характеристики данных. Если данные обладают четкой и линейной структурой, можно использовать методы, такие как K-средние. Если же структура сложная и имеет высокую плотность в некоторых областях, лучше применить DBSCAN или иерархическую кластеризацию. Кроме того, всегда стоит уделить внимание качеству данных, предварительная очистка которых может существенно повысить точность модели.
Как настроить параметры гиперпараметров для повышения качества моделей

Основными гиперпараметрами, которые обычно требуют настройки, являются скорость обучения (learning rate), количество слоёв в нейронной сети, размер мини-батча (batch size), количество деревьев в случайном лесе, и параметры регуляризации. Примером гиперпараметра является коэффициент регуляризации в линейной регрессии, который помогает избежать переобучения модели, позволяя контролировать степень штрафа за слишком большие веса.
Оптимизация гиперпараметров часто начинается с выбора метода поиска, который можно разделить на два основных подхода: вручную и с использованием автоматизированных методов. Ручная настройка требует анализа результатов модели после каждого изменения, что может занять много времени и ресурсов. В свою очередь, автоматические методы, такие как сеточный поиск (Grid Search) или случайный поиск (Random Search), предоставляют более систематичный способ перебора значений гиперпараметров, увеличивая вероятность нахождения оптимальных значений.
Для более сложных моделей, таких как нейронные сети, часто используют методы оптимизации гиперпараметров, такие как Байесовская оптимизация или алгоритмы градиентного спуска для поиска минимальной ошибки. Эти методы эффективно справляются с задачей настройки гиперпараметров за счёт учета предыдущих испытаний и на основе этого строят модель, которая предсказывает, какие значения гиперпараметров могут привести к наилучшему результату.
Важным аспектом является кросс-валидация, которая помогает предотвратить переобучение при настройке гиперпараметров. Например, кросс-валидация с k-складыми позволяет оценить модель на нескольких различных подмножествах данных, улучшая её обобщаемость.
Кроме того, для некоторых моделей существует ряд готовых рекомендаций по настройке гиперпараметров, основанных на теоретических и эмпирических исследованиях. Однако важно помнить, что каждая задача может требовать индивидуальной настройки, и универсальные методы не всегда дают идеальный результат.
Ключевым моментом является мониторинг производительности модели на этапе настройки. Использование таких метрик, как точность (accuracy), ошибка (error), или F1-меры, помогает правильно интерпретировать, какие изменения гиперпараметров привели к улучшению модели.







